2. JIT-compilation, Functional Programming and Gradients#
2.1. Just-In-Time (JIT) compilation#
2.1.1. What is JIT compilation?#
Just-In-Time (JIT) compilation is a technique used to improve the performance of code at runtime. When a function is JIT compiled, it is transformed from its original form into optimized machine code, allowing it to execute more efficiently. JAX’s JIT compiler operates on Python functions, analyzing and optimizing them for improved performance. The JAX just-in-time (JIT) compiler accelerates logic within functions by fusing linear algebra operations into a single optimized kernel that the host can launch on the GPU / TPU (or CPU if no accelerator is detected).
2.1.2. Benefits of JIT Compilation#
Faster Execution: JIT compilation can significantly speed up the execution of numerical code by optimizing it for the underlying hardware.
Reduced Overhead: Compiled functions have lower overhead compared to interpreted Python code, leading to improved performance.
Dynamic Optimization: JIT compilers can adaptively optimize code based on runtime characteristics, leading to better performance in real-world scenarios.
2.1.3. How to Use JIT Compilation with JAX?#
JAX provides the jit function, which can be used to JIT compile a Python function.
Let’s start with an example
import jax
import jax.numpy as jnp
def f(x):
a = 3*x + jnp.sin(x) + jnp.cos(x**2) - jnp.cos(2*x) - x**2 * 0.4 * x**1.5
return jnp.sum(a)
Let’s build an array to call the function on.
n = 50_000_000
x = jnp.ones(n)
How long does the function take to execute?
%time f(x).block_until_ready()
CPU times: user 1.22 s, sys: 281 ms, total: 1.5 s
Wall time: 852 ms
Array(2.1989598e+08, dtype=float32)
Note
Here, in order to measure actual speed, we use the
block_until_ready()method to hold the interpreter until the results of the computation are returned from the device. This is necessary because JAX uses asynchronous dispatch, which allows the Python interpreter to run ahead of GPU computations.
The code doesn’t run as fast as we might hope, given that it’s running on a GPU.
But if we run it a second time it becomes much faster:
%time f(x).block_until_ready()
CPU times: user 1.04 s, sys: 260 ms, total: 1.3 s
Wall time: 661 ms
Array(2.1989598e+08, dtype=float32)
This is because the built in functions like jnp.cos are JIT compiled and the
first run includes compile time.
Why would JAX want to JIT-compile built in functions like jnp.cos instead of
just providing pre-compiled versions, like NumPy?
The reason is that the JIT compiler can specialize on the size of the array being used, which is helpful for parallelization.
For example, in running the code above, the JIT compiler produced a version of jnp.cos that is
specialized to floating point arrays of size n = 50_000_000.
We can check this by calling f with a new array of different size.
m = 50_000_001
y = jnp.ones(m)
%time f(y).block_until_ready()
CPU times: user 1.22 s, sys: 262 ms, total: 1.49 s
Wall time: 841 ms
Array(2.1989598e+08, dtype=float32)
Notice that the execution time increases, because now new versions of
the built-ins like jnp.cos are being compiled, specialized to the new array
size.
If we run again, the code is dispatched to the correct compiled version and we get faster execution.
%time f(y).block_until_ready()
CPU times: user 1.02 s, sys: 294 ms, total: 1.32 s
Wall time: 669 ms
Array(2.1989598e+08, dtype=float32)
The compiled versions for the previous array size are still available in memory too, and the following call is dispatched to the correct compiled code.
%time f(x).block_until_ready()
CPU times: user 1.03 s, sys: 285 ms, total: 1.31 s
Wall time: 666 ms
Array(2.1989598e+08, dtype=float32)
2.1.3.1. Compiling the outer function#
We can do even better if we manually JIT-compile the outer function.
f_jit = jax.jit(f) # target for JIT compilation
Let’s run once to compile it:
f_jit(x)
Array(2.1989598e+08, dtype=float32)
And now let’s time it.
%time f_jit(x).block_until_ready()
CPU times: user 1.61 s, sys: 18.5 ms, total: 1.63 s
Wall time: 421 ms
Array(2.1989598e+08, dtype=float32)
Note the speed gain.
This is because the array operations are fused and no intermediate arrays are created.
Incidentally, a more common syntax when targetting a function for the JIT compiler is
@jax.jit
def f(x):
a = 3*x + jnp.sin(x) + jnp.cos(x**2) - jnp.cos(2*x) - x**2 * 0.4 * x**1.5
return jnp.sum(a)
2.1.4. Limitations and Considerations#
While JIT compilation can improve performance, there are some limitations and considerations to keep in mind:
Compilation Overhead: There may be an initial overhead associated with compiling the function, especially for small functions or infrequently executed code.
Memory Usage: Compiled functions may consume more memory due to the generated machine code.
Dynamic Features: Some Python features, such as dynamic control flow or variable-length data structures, may limit the effectiveness of JIT compilation.
2.2. Functional Programming#
From JAX’s documentation:
When walking about the countryside of Italy, the people will not hesitate to tell you that JAX has “una anima di pura programmazione funzionale”.
In other words, JAX assumes a functional programming style.
The major implication is that JAX functions should be pure.
A pure function will always return the same result if invoked with the same inputs.
In particular, a pure function has
no dependence on global variables and
no side effects
JAX will not usually throw errors when compiling impure functions but execution becomes unpredictable.
Here’s an illustration of this fact, using global variables:
a = 1 # global
@jax.jit
def f(x):
return a + x
x = jnp.ones(2)
f(x)
Array([2., 2.], dtype=float32)
In the code above, the global value a=1 is fused into the jitted function.
Even if we change a, the output of f will not be affected — as long as the same compiled version is called.
a = 42
f(x)
Array([2., 2.], dtype=float32)
Changing the dimension of the input triggers a fresh compilation of the function, at which time the change in the value of a takes effect:
x = jnp.ones(3)
f(x)
Array([43., 43., 43.], dtype=float32)
Moral of the story: write pure functions when using JAX!
2.3. Automatic Differentiation#
2.3.1. What is Automatic Differentiation?#
Automatic Differentiation (AD) is a technique for efficiently computing derivatives of functions, including gradients and higher-order derivatives, with respect to their inputs. Unlike numerical or symbolic differentiation, AD leverages the chain rule to decompose complex functions into simpler elementary operations.
2.3.2. Theory Behind Automatic Differentiation#
AD computes derivatives by recursively applying the chain rule to decompose a function into elementary operations, known as “primal” and “tangent” evaluations. It can be implemented using two modes: forward-mode AD and reverse-mode AD, each suited for different use cases.
2.3.3. Gradients#
JAX provides the grad function to compute gradients of scalar functions. Let’s see a simple example:
# Define a function
def f(x):
return jnp.cos(jnp.sin(x**2))
# Compute the gradient of the function
f_prime = jax.grad(f)
print("Gradient of f:", f_prime(10.0))
Gradient of f: 8.364531
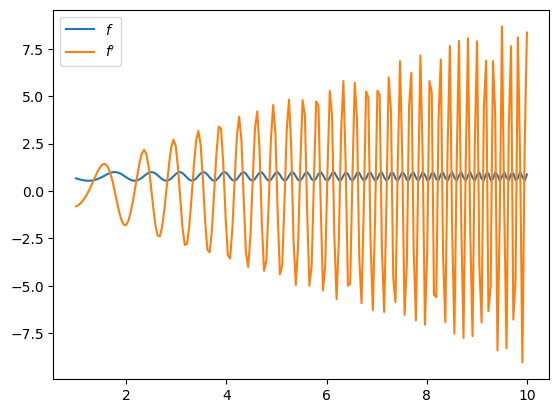
Let’s plot the function and derivative, noting that \( f'(x) = x \).
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
x_grid = jnp.linspace(1, 10, 200)
ax.plot(x_grid, f(x_grid), label="$f$")
ax.plot(x_grid, [f_prime(x) for x in x_grid], label="$f'$")
ax.legend(loc='upper left')
plt.show()
JAX’s grad function can also compute gradients of functions with multiple arguments. Let’s see an example of computing the gradient of a function with respect to multiple variables:
# Define a function of two variables
def g(x, y):
return jnp.sin(x) * jnp.cos(y)
# Compute the gradient of g with respect to both x and y
g_prime = jax.grad(g, argnums=(0, 1))
# Evaluate the gradient at (x, y) = (0, 0)
result = g_prime(0.0, 0.0)
print("Gradient of g at (0, 0):", result)
Gradient of g at (0, 0): (Array(1., dtype=float32, weak_type=True), Array(-0., dtype=float32, weak_type=True))
In this example, argnums=(0, 1) specifies that we want to compute the gradient with respect to both the first and second arguments of the function g.
2.3.3.1. Using jax.value_and_grad for Function and Gradient Computation#
JAX provides the value_and_grad function to compute both the function value and its gradient simultaneously, improving efficiency. Here’s an example:
# Compute the function value and gradient simultaneously
value, grad_value = jax.value_and_grad(f)(jnp.array(3.0))
print("Function value:", value)
print("Gradient of f at x=3.0:", grad_value)
Function value: 0.9162743
Gradient of f at x=3.0: 2.1897266
2.3.4. Computing Hessian#
The hessian function computes the Hessian matrix of the function f, which represents the matrix of second-order partial derivatives.
# Compute the Hessian matrix of f
hessian_f = jax.hessian(f)
# Evaluate the Hessian at x = 2
result = hessian_f(2.0)
print("Hessian of f at x=2:", result)
Hessian of f at x=2: 2.4463372
The hessian function computes the Hessian matrix of the function f, which represents the matrix of second-order partial derivatives.
2.3.5. Computing Jacobians#
JAX provides a jacobian function to compute the Jacobian matrix of a vector-valued function.
Let’s see an example
# Define a vector-valued function
def h(x):
return jnp.array([x[0] ** 2, jnp.sin(x[1])])
# Compute the Jacobian of h using forward-mode differentiation
jacobian_h = jax.jacfwd(h)
# Evaluate the Jacobian at x = [1, 0]
result = jacobian_h(jnp.array([1.0, 0.0]))
print("Jacobian of h at [1, 0]:", result)
Jacobian of h at [1, 0]: [[2. 0.]
[0. 1.]]